取样自适应偏移
取样自适应偏移(英语:Sample Adaptive Offset,缩写:SAO)为H.265/高效率视讯编码[1]内嵌式滤波器的一种,其余两种内嵌式循环滤波器分别是:去区块效应滤波器(Deblocking Filter)、调适性循环滤波器(Adaptive Loop Filter)。
介绍
高效率视讯编码使用4x4至32x32大小的转换单元,而H.264/高阶视讯编码使用的转换单元不超过8x8,越大的转换单元会产生更多的假影(Artifacts)包含量化所造成的振铃现象;此外,高效率视讯编码8阶分数亮度取样差值和4阶分数彩度取样差值,而H.264/高阶视讯编码分别使用6阶分数亮度取样差值和2阶的分数彩度取样差值,越高阶的取样差值会造成越严重的振铃现象(Ringing Artifacts),因此高效率视讯编码需要引入新的内嵌式循环滤波器,除了开发去区块效应滤波器,更进一步引入全新概念的取样自适应偏移滤波器。取样自适应偏移借由类重建的样本为数个类来降低取样的失真,过程中会取得每一类的偏移量,然后再将偏移量分别加到每一类里的样本,而每一类的偏移量会在编码器里适当地计算出且明确地将资讯给解码器,以有效降低取样失真,为了节省边资讯(Side Information),样本类会在编码器和解码器中实现;为了在只有一编码树单元的情况下达到低延迟,基于编码树单元的句法被设计成可以指定取样自适应偏移的系数,此基于编码树单元最佳化算法可以导出每一编码树单元的取样自适应偏移系数,并且将取样自适应偏移系数交错放入边资料(Slide Data)。[2]
取样处理过程
{kind=link}
取样自适应偏移会根据样本的类和适用的区域而使用不同的偏移量,两种取样自适应偏移型态可以满足高效率视讯编码对于低运算量的要求,分别是:边缘偏移、带偏移,边缘偏移的样本类是基于比较当前样本以及邻近样本,而带偏移的样本类是基于样本值。为达到低编码延迟以及减少缓冲区的使用量,类区域的大小会固定成一个编码树区块的大小,若要再降低边资讯的资料量,可以合并多个编码树单元共用取样自适应偏移参数。[2]
边缘偏移(Edge Offset)
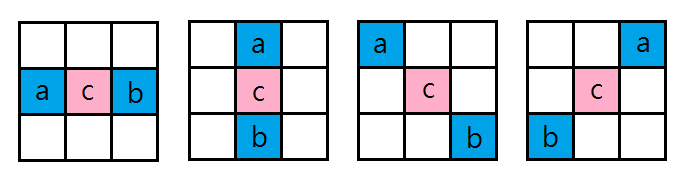
为了保持运算复杂度和编码效率的平衡,边缘偏移使用4种样本类的一维方向图形,分别为:水平、垂直、135度对角、45度对角,如图一所示,"c"代表当前的样本,"a"和"b"则代表邻近的样本,每一种模式分别对应图一的4种图形。在编码时,每一编码树区块只能选择一种边缘偏移类,且基于优化失真率的考量,最佳的边缘偏移类会以位元流(Bitstream)当作边资讯传送,又因为这些边缘偏移图形都是一维,所以类的结果不会确切地和临界样本相关。[2]
{kind=link}
对于一个给定的边缘偏移类(Class),在编码树区块内的每个样本会被分为5种形态(Category)中的其一,当前样本"a"会根据选择的一维方向模式和两相邻样本"b"、"c"比较,比较的规则如下表:
| 型态 | 条件 | |
|---|---|---|
| 1 | c < a && c < b | |
| 2 | (c < a && c == b) | (c == a && c < b) |
| 3 | (c > a && c == b) | (c == a && c > b) |
| 4 | c > a && c > b | |
| 0 | 不符合以上的条件 |
型态1及4分别关联相对低值和相对峰值,型态2及3分别关联凹面及凸面,若当前样本无法归于上面4种型态,则为型态0且将不适用取样自适应偏移。这4种型态的意义以及其正负值如图二表示,在边缘偏移型态1和2中使用正偏移使得相对低值及凹面更平滑,若是使用负偏移则会使的图形更尖锐;而在边缘偏移型态3和4中使用负偏移使得相对峰值及凸面更平滑,使用正偏移则更尖锐。
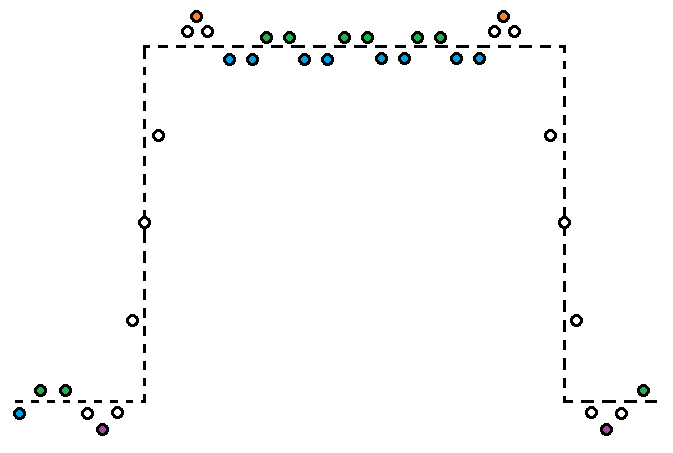
图三说明了著名的吉布斯现象(Gibbs Phenomenon),可以用来模拟一些影像压缩的假象,特别是振铃现象(Ringing Artifacts),虽然水平轴和垂直轴没有特别标记,但分别定义沿着一维路径的样本位置和样本值,虚线代表原始的样本,有色的实心圆代表相对低值、相对峰值、凸面、和凹面,其余样本则为空心圆。若在相对峰值、凸面使用负偏移,而在相对低值、凹面使用正偏移,可以有效减少失真。
{kind=link}
带偏移(Band Offset)
带偏移为增加一偏移量至同一带上的所有样本,样本的值域被等分为32带,一个8位元样本的值域为0到255,其宽度为8,取样值从8k至8k+7属于带k,而k的范围是0至31,而解码器会得知在同一带中原始样本和重建样本的平均差。解码器只有4个连续带和起始带位置的偏移资讯,为了减少线性缓冲区的需求,这些由解码器可取得的偏移量数目由16减少至4,而此数目正好相等于解码器可得到的边缘偏移量数目;而另一个会选择只有4个带的理由是这些区域经由图片从四元树分割成编码树区块而减少时,可以有效限制在一个区域中的取样范围。[2]
编码算法
一张图片会被切割成多层的四元树区域,为了决定取样自适应偏移的系数,下列为处理的过程:
- 1. 根据图片大小,决定最大四元树阶层L。
- 2. 分割图片至最小四元树阶层L的区域。
- 3. 从每一最小区域收集所有取样自适应偏移的类型统计资料。
- 4. 使k = L。
- 5. 导出每一区域阶层为k的取样自适应偏移型态参数。
- 6. 选出位元率-失真(Rate-Distortion)最小的取样自适应偏移型态。
- 7. 结合每一阶层为k-1的父区域和阶层为k的子区域的统计资料。
- 8. 对于每一阶层为k-1的父区域,根据失真率而决定是否合并阶层为k的子区域。
- 9. 使k = k – 1,若k大于0则跳至步骤5继续,否则结束。
[3] 以下说明如何从取样自适应偏移编码器的四元树切割得到统计资料,Nl,i,t,c为在阶层l、区域i、类t、型态c的像素数目,al,i,t,c为相对应的偏移,el,i,t,c为相对应原始讯号和重建讯号差的合,Rl,i,t为相关偏移的预测率,借由使用收集到的统计资料,可以利用简单的式子计算出预测的失真减少量,Dl,i,t为阶层l、区域i、类t、型态c的预测失真减少量。
Dl,i,t = (Nl,i,t,ca2l,i,t,c - 2al,i,t,cel,i,t,c)(1)
得知预测失真减少量之后,我们可以计算出位元率-失真成本(Rate-Distortion-Cost),λ为拉格朗日乘数。
Jl,i,t = Dl,i,t + λRl,i,t(2)
编码器会根据式子(4)选择有最低位元率-失真成本且在阶层l、区域i的类,T为取样自适应偏移类的集合。
Jl,i = (Jl,i,t)(3) tl,i = (Jl,i,t)(4)
得到最低位元率-失真成本以及最佳取样自适应偏移类之后,编码器会尝试合并子区域成一个父区域,J’l,t和t’l,i分别是合并后的位元率-失真成本以及选择的取样自适应偏移类,Ωl,i是阶层l和区域i的集合。
J'l,i = ( Jl+1,k,Jl,i)(5) t'l,i = ( Jl+1,k,Jl,i)(6)
根据合并子区域后的结果,相关父区域的分离资讯由以下公式决定:
Sl,i为1代表当前区域会被切割成若干个子区域,为0则代表当前区域不会被切割,处理所有阶层k的区域后,编码器会继续处理阶层k-1的区域直到阶层0的区域,最后使用决定的取样自适应偏参数更新每一区域的解码器图像缓冲区。
参考资料
- ^ G.J. Sullivan; J.-R. Ohm; W.-J. Han; T. Wiegand. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Transactions on Circuits and Systems for Video Technology. 2012-12 [2013-06-25]. (原始内容存档于2019-08-08).
- ^ 2.0 2.1 2.2 2.3 Chih-Ming Fu; E. Alshina; A. Alshin; Yu-Wen Huang; Ching-Yeh Chen; Chia-Yang Tsai; Chih-Wei Hsu; Shaw-Min Lei; Jeong-Hoon Park; Woo-Jin Han. Sample Adaptive Offset in the HEVC Standard. IEEE Transactions on Circuits and Systems for Video Technology. 2011-10.
- ^ Chih-Ming Fu; Ching-Yeh Chen; Yu-Wen Huang; Shawmin Lei. Sample adaptive offset for HEVC. 2011 IEEE 13th International Workshop on Multimedia Signal Processing (MMSP). 2011-10.