统计机器翻译
统计机器翻译(英语:Statistical Machine Translation,简写为SMT)是机器翻译的一种,也是目前非限定领域机器翻译中性能较佳的一种方法。统计机器翻译的基本思想是通过对大量的平行语料进行统计分析,构建统计翻译模型,进而使用此模型进行翻译。从早期基于词的机器翻译已经过渡到基于短语的翻译,并正在融合句法信息,以进一步提高翻译的精确性。
2016年前Google翻译的大部分语言对采用的都是统计机器翻译的方法[1]。而Google亦在此本领域保持领先地位,在美国国家标准局组织的机器翻译评测中遥遥领先。[2]但Google翻译在2016年11月开始使用神经机器翻译作为主要翻译系统,并开发了Google神经机器翻译系统。此外,常用的基于统计法机器翻译的系统还包括Bing翻译[3]和百度翻译等。
统计机器翻译的首要任务是为语言的产生构造某种合理的统计模型,并在此统计模型基础上,定义要估计的模型参数,并设计参数估计算法。早期的基于词的统计机器翻译采用的是噪声信道模型,采用最大似然准则进行无监督训练,而近年来常用的基于短语的统计机器翻译则采用区分性训练方法,一般来说需要参考语料进行有监督训练。
历史
早在1949年,瓦伦·韦弗就基于香农的信息论提出了统计机器翻译的基本思想[4]。而最早提出可行的统计机器翻译模型的是IBM研究院的研究人员。他们在著名的文章《统计机器翻译的数学理论:参数估计》[5]中提出了由简及繁的五种词到词的统计模型,分别被称为IBM Model 1到IBM Model 5。这五种模型均为噪声信道模型,而其中所提出的参数估计算法均基于最大似然估计。然而由于计算条件的限制和平行语料库的缺乏,尚无法实现基于大规模数据的计算。其后,由Stephan Vogel提出了基于隐马尔科夫模型的统计模型也受到重视,被认为可以较好的替代IBM Model 2[6].
在此文发表后6年,即1999年,约翰·霍普金斯大学夏季讨论班集中了一批研究人员实现了GIZA软件包[7],实现了IBM Model 1到IBM Model 5。Franz-Joseph Och在随后对GIZA进行了优化,加快了训练速度,特别是IBM Model 3到5的训练。同时他还提出了更加复杂的Model 6。Och发布的软件包被命名为GIZA++[8],直到现在,该软件包还是绝大部分机器翻译系统的基石。目前,针对大规模语料的训练,已有GIZA++的若干并行化版本存在。[9]
基于词的统计机器翻译虽然开辟了统计机器翻译这条道路,其性能却由于建模单元过小而受到极大限制。同时,产生性(generative)模型使得模型适应性较差。因此,许多研究者开始转向基于短语的翻译方法。Franz-Josef Och再次凭借其出色的研究,推动了统计机器翻译技术的发展,他提出的基于最大熵模型的区分性训练方法使得统计机器翻译的性能极大提高并在此后数年间远远超过其他方法[10]。更进一步的,Och又提出修改最大熵方法的优化准则,直接针对客观评价标准进行优化,从而产生了今天广泛采用的最小错误训练方法(Minimum Error Rate Training)[11]。
另一件促进统计机器翻译进一步发展的重要发明是翻译结果自动评价方法的出现,这些方法为翻译结果提供了客观的评价标准,从而避免了人工评价的繁琐与昂贵。这其中最为重要的评价是BLEU评价指标[12]。虽然许多研究者抱怨BLEU与人工评价相差甚远,并且对于一些小的错误极其敏感,绝大部分研究者仍然使用BLEU作为评价其研究结果的首要(如果不是唯一)的标准。 于2012年提出的LEPOR评价指标[13]在权威的计算语言学会统计机器翻译Workshop(ACL-WMT)的八个语言对语料上的实验得到了比BLEU与人的评价更高相关性的分数[14]。
Moses是目前维护较好的开源机器翻译软件,由爱丁堡大学研究人员组织开发。其发布使得以往繁琐复杂的处理简单化[15]。
模型
噪声信道模型
噪声信道模型假定,源语言中的句子 (信宿)是由目标语言中的句子 (信源)经过含有噪声的信道编码后得到的。那么,如果已知了信宿 和信道的性质,我们可以得到信源产生信宿的概率,即 。而寻找最佳的翻译结果 也就等同于寻找:
利用贝叶斯公式,并考虑对给定 , 为常量,上式即等同于
由此,我们得到了两部分概率:
- ,指给定信源,观察到信号的概率。在此称为翻译模型。
- ,信源发生的概率。在此称为语言模型
可以这样理解翻译模型与语言模型,翻译模型是一种语言到另一种语言的词汇间的对应关系,而语言模型则体现了某种语言本身的性质。翻译模型保证翻译的意义,而语言模型保证翻译的流畅。从中国对翻译的传统要求“信达雅”三点上看,翻译模型体现了信与达,而雅则在语言模型中得到反映。
原则上任何语言模型均可以应用到上述公式中,因此以下讨论集中于翻译模型。在IBM提出的模型中,翻译概率被定义为:
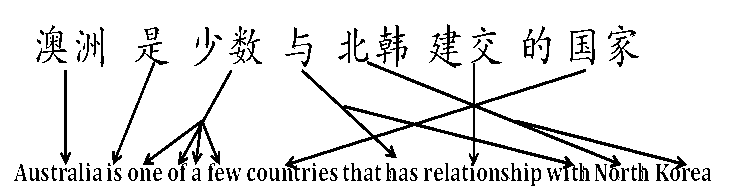{kind=link}
其中的 被定义为隐含变量——词对齐(Word Alignment),所谓词对齐,简而言之就是知道源语言句子中某个词是由目标语言中哪个词翻译而来的。例如右图中,一个词可以被翻译为一个或多个词,甚至不被翻译。于是,获取翻译概率的问题转化为词对齐问题。IBM系列模型及HMM, Model 6都是词对齐的参数化模型。它们之间的区别在于模型参数的数量,类型各不相同。例如IBM Model 1,唯一的参数是词翻译概率,与词在句子中的位置无关。也就是说:
其中 是词对齐中的一条连接,表示源语言中的第 个词翻译到目标语言中的第 个词。注意这里的翻译概率是词之间而非位置之间的。IBM Model 2的参数中增加了词在句子中的位置,公式为:
其中 分别为源、目标语言的句子长度。
HMM模型将IBM Model 2中的绝对位置更改为相对位置,即相对上一个词连接的位置,而IBM Model 3,4,5及Model 6引入了“Fertility Model”,代表一个词翻译为若干词的概率。
在参数估计方面,一般采用最大似然准则进行无监督训练,对于大量的“平行语料”,亦即一些互为翻译的句子
由于并没有直接的符号化最优解,实践中采用EM算法。首先,通过现有模型,对每对句子估计 全部可能的(或部分最可能的)词对齐的概率,统计所有参数值发生的加权频次,最后进行归一化。对于IBM Model 1,2,由于不需要Fertility Model,有简化公式可获得全部可能词对齐的统计量,而对于其他模型,遍历所有词对齐是NP难的。因此,只能采取折衷的办法。首先,定义Viterbi对齐为当前模型参数 下,概率最大的词对齐:
在获取了Viterbi对齐后,可以只统计该对齐结果的相关统计量,亦可以根据该对齐,做少许修改后(即寻找“临近”的对齐)后再计算统计量。IBM 3,4,5及Model 6都是采用这种方法。
目前直接采用噪声信道模型进行完整机器翻译的系统并不多见,然而其副产品——词对齐却成为了各种统计机器翻译系统的基石。时至今日,大部分系统仍然首先使用GIZA++对大量的平行语料进行词对齐。由于所面对的平行语料越来越多,对速度的关注使得MGIZA++,PGIZA++等并行化实现得到应用。噪声信道模型和词对齐仍然是研究的热点,虽然对于印欧语系诸语言,GIZA++的对齐错误率已经很低,在阿拉伯语,中文等语言与印欧语系语言的对齐中错误率仍然很高。特别是中文,错误率常常达到30%以上。所谓九层之台,起于累土,缺乏精确的词对齐是中文机器翻译远远落后于其他语言的原因。虽然目前出现了一些区分性词对齐技术,无监督对齐仍然是其中的重要组成部分。[16]
判别式模型
判别式模型噪声信道模型(产生式模型)不同,它不应用贝叶斯公式,而是直接对条件概率 建模。
特征函数
在这个框架下, 个特征函数
通过参数化公式
其中 是每个特征函数的权重,也是模型所要估计的参数集,记为 。基于这个模型,获取给定源语言句子 ,最佳翻译 的决策准则为:
简而言之,就是找到使得特征函数最大的解。
原则上,任何特征函数都可以被置于此框架下,噪声信道模型中的翻译模型、语言模型都可以作为特征函数。并且,在产生式模型中无法使用的“反向翻译模型”,即 也可以很容易的被引入这个框架中。目前基于短语的翻译系统中,最常用的特征函数包括
- 短语翻译概率
- 词翻译概率(短语中每个词的翻译概率)
- 反向短语翻译概率
- 反向词翻译概率
- 语言模型
而一些基于句法的特征也在被加入。
优化准则
优化准则指的是给定训练语料,如何估计模型参数 。一般来说,训练模型参数需要一系列已翻译的文本,每个源语言句子 拥有 个参考翻译 。
早期,区分性训练被置于最大熵准则下,即:
这一准则简单快速且由于优化目标是凸的,收敛速度快。然而,一个极大的问题是,“信息熵”本身和翻译质量并无联系,优化信息熵以期获得较好的翻译结果在逻辑上较难说明。借助客观评价准则如BLEU,希望直接针对这些客观准则进行优化能够提升翻译性能。由此而产生最小化错误率训练算法。通过优化系统参数,使得翻译系统在客观评价准则上的得分越来越高,同时,不断改进客观评价准则,使得客观评价准则与主观评价准则越来越接近是目前统计机器翻译的两条主线。
使用这些客观评价准则作为优化目标,即:
的一个主要问题是,无法保证收敛性。并且由于无法得到误差函数(即客观评价准则) 的导数,限制了可使用的优化方法。目前常用的方法多为改进的Powell法,一般来说训练时间颇长且无法针对大量数据进行训练。
调序模型
许多语言对的语序是有很大差别的。在前述词对齐模型中,包含有词调序模型,在区分性训练中也需要较好的调序模型。调序模型可以是基于位置,也就是描述两种语言每个句子不同位置的短语的调序概率,也可以是基于短语本身,例如Moses中的调序模型即是基于短语本身,描述在给定当前短语对条件下,其前后短语对是否互换位置。由于现实中的调序模型远非“互换位置”这么简单,而是牵涉句法知识,调序的效果仍然不佳。目前重定位问题还是机器翻译中亟待解决的问题。
解码
无论采用哪种模型,在进行实际翻译过程中,都需要进行解码。所谓解码,即是指给定模型参数和待翻译句子,搜索使概率最大(或代价最小)的翻译结果的过程。同许多序列标注问题,例如中文分词问题类似,解码搜索可以采用分支定界或启发式深度优先搜索(A*)方法。一般来说,搜索算法首先构造搜索网络,也就是将待翻译句子与可能的翻译结果融合为一个加权有限状态转换机(Weighted Finite State Transducer),而后在此网络上搜索最优路径。
基本流程
统计机器翻译同大多数的机器学习方法相类似,有训练及解码两个阶段,其中训练阶段的目标是获得模型参数,而解码阶段的目标则是利用所估计的参数和给定的优化目标,获取待翻译语句的最佳翻译结果。对于基于短语的统计机器翻译来说,“训练”阶段较难界定,严格来说,只有最小错误率训练一个阶段可称为训练。但是一般来说,词对齐和短语抽取阶段也被归为训练阶段。[17]
语料获取及预处理
语料预处理阶段,需要搜集或下载平行语料,所谓平行语料,指的是语料中每一行的两个句子互为翻译。目前网络上有大量可供下载的平行语料。搜寻适合目标领域(如医疗、新闻等)的语料是提高特定领域统计机器翻译系统性能的重要方法。
在获取语料后,需要进行一定得文本规范化处理,例如对英语进行词素切分,例如将's独立为一个词,将与词相连的符号隔离开等。而对中文则需要进行分词。同是,尽可能过滤一些包含错误编码的句子,过长的句子或长度不匹配(相差过大)的句子。
获取的语料可分为三部分,第一部分用于词对齐及短语抽取,第二部分用于最小错误率训练,第三部分则用于系统评价。第二第三部分的数据中,每个源语言句子最好能有多条参考翻译。
词对齐
首先,使用GIZA++对平行语料进行对齐。由于GIZA++是“单向”的词对齐,故而对齐应当进行两次,一次从源到目标,第二次从目标到源。一般来说,GIZA++需要依次进行IBM Model 1, HMM及IBM Model 3,4的对齐,因IBM Model 2对齐效果不佳,而IBM Model 5耗时过长且对性能没有较大贡献。根据平行语料的大小不同及所设置的迭代次数多少,训练时间可能很长。一个参考数据为,1千万句中文-英文平行语料(约3亿词)在Intel Xeon 2.4GHz服务器上运行时间约为6天[9]。如果耗时过长可考虑使用MGIZA++和PGIZA++进行并行对齐(PGIZA++支持分布式对齐)。
其后,对两个方向的GIZA++对齐结果进行合并,供短语抽取之用。
短语抽取
短语抽取的基本准则为,两个短语之间有至少一个词对有连接,且没有任何词连接于短语外的词。Moses软件包包含短语抽取程序,抽取结果将占有大量的磁盘空间。建议若平行语料大小达到1千万句,短语最大长度大于等于7,至少应准备500GB的存储空间。
短语特征准备
在短语抽取完毕后,可进行短语特征提取,即计算短语翻译概率及短语的词翻译概率。该需要对抽取的所有短语进行两次排序,一般来说,中等规模(百万句语料)的系统亦需要进行外部排序,磁盘读写速度对处理时间影响极大。建议在高速磁盘上运行。参考运行时间及磁盘空间消耗:前述千万句语料库,限制短语长度7,外部排序运行于SCSI Raid 0+1磁盘阵列,运行时间3日11小时,峰值磁盘空间消耗813GB。[18]
语言模型训练
语言模型训练请参考语言模型。在区分性训练框架下,允许使用多个语言模型,因此,使用由大语料训练得到的无限领域语言模型配合领域相关的语言模型能够得到最好的效果。
最小化错误率训练
最小化错误率训练通过在所准备的第二部分数据——优化集(Tuning Set)上优化特征权重 ,使得给定的优化准则最优化。一般常见的优化准则包括信息熵、BLEU、TER等。这一阶段需要使用解码器对优化集进行多次解码,每次解码产生N个得分最高的结果,并调整特征权重。当权重被调整时,N个结果的排序也会发生变化,而得分最高者,即解码结果,将被用于计算BLEU得分或TER。当得到一组新的权重,使得整个优化集的得分得到改进后,将重新进行下一轮解码。如此往复直至不能观察到新的改进。
根据选取的N值的不同,优化集的大小,模型大小及解码器速度,训练时间可能需要数小时或数日。
解码及系统评价
使用经最小化错误率训练得到的权重,即可进行解码。一般此时即可在测试集上进行系统性能评价。在客观评价基础上,有一些有条件的机构还常常进行主观评价。
难点及研究方向
{kind=link}
统计机器翻译的难点主要在于模型中所包含句法、语义成分较低,因而在处理句法差别较大的语言对,例如中文-英文时将遇到问题。有时翻译结果虽然“词词都对”却无法被人阅读。可以说目前主流(如Moses)统计机器翻译仍然处于机器翻译金字塔的底层。目前大量的研究集中于将句法知识引入框架中,例如使用依存文法限制翻译路径,等。
同时,统计机器翻译依赖巨大的语料库,随着语料库资源越来越丰富和算法的日趋复杂,处理这些语料需要越来越强大的计算能力。长期以来,Google在机器翻译领域的领先地位就得益于其强大的分布式计算能力。随着分布式计算的普及,将机器翻译相关技术并行化将是另一研究热点。
最后,机器翻译依赖客观评价准则,而客观评价准则最终要与主观评价准则挂钩。每年各类机器翻译相关的会议上都会有若干关于客观评价准则的研究发表,总的来说,评价翻译的优劣本身就是一个人工智能问题,其难度绝不在机器翻译之下。
参考文献
- ^ Google Translate FAQ http://www.google.com/intl/en/help/faq_translation.html (页面存档备份,存于互联网档案馆)
- ^ NIST 2006 Machine Translation Evaluation Official Results http://www.nist.gov/speech/tests/mt/2006/doc/mt06eval_official_results.html (页面存档备份,存于互联网档案馆)
- ^ Microsoft Translator Help http://www.microsofttranslator.com/help/?FORM=R5FD (页面存档备份,存于互联网档案馆)
- ^ W. Weaver (1955). Translation (1949). In: Machine Translation of Languages, MIT Press, Cambridge, MA.
- ^ P. Brown, S. Della Pietra, V. Della Pietra, and R. Mercer (1993). The mathematics of statistical machine translation: parameter estimation. Computational Linguistics, 19(2), 263-311.
- ^ S. Vogel, H. Ney and C. Tillmann. 1996. HMM-based Word Alignment in StatisticalTranslation. In COLING’96: The 16th International Conference on Computational Linguistics, pp. 836-841, Copenhagen, Denmark.
- ^ Y. Al-Onaizan, J. Curin, M. Jahr, K. Knight, J. D. Lafferty, I. Melamed, D. Purdy, F. Och, N. A. Smith and D. Yarowsky. 1999. Statistical Machine Translation. Final Report JHU Workshop, Available at http://www.clsp.jhu.edu/ws99/projects/mt/final_report/mtfinal-reports.ps[永久失效链接]
- ^ F. Och and H. Ney. (2003). A Systematic Comparison of Various Statistical Alignment Models. Computational Linguistics, 29(1):19-51
- ^ 9.0 9.1 Q. Gao, S. Vogel, "Parallel Implementations of Word Alignment Tool", Software Engineering, Testing, and Quality Assurance for Natural Language Processing, pp. 49-57, June, 2008
- ^ F. Och, H. Ney. "Discriminative Training and Maximum Entropy Models for Statistical Machine Translation". In "ACL 2002: Proc. of the 40th Annual Meeting of the Association for Computational Linguistics" (best paper award), pp. 295-302, Philadelphia, PA, July 2002.
- ^ F. Och. "Minimum Error Rate Training for Statistical Machine Translation". In "ACL 2003: Proc. of the 41st Annual Meeting of the Association for Computational Linguistics", Japan, Sapporo, July 2003.
- ^ K. Papineni, S. Roukos, T. Ward and W. Zhu 2002. BLEU: a Method for Automatic Evaluation of machine translation. Proc. of the 40th Annual Conf. of the Association for Computational Linguistics (ACL 02), pp. 311-318, Philadelphia, PA
- ^ Aaron L.-F. Han, Derek F. Wong and Lidia S. Chao 2012. LEPOR: A Robust Evaluation Metric for Machine Translation with Augmented Factors. Proc. of the 24th International Conference on Computational Linguistics (COLING 2012): Posters, pages 441–450, Mumbai, India
- ^ 存档副本 (PDF). [2013-07-19]. (原始内容 (PDF)存档于2013-04-09).
- ^ P. Koehn, H. Hoang, A. Birch, C. Callison-Burch, M. Federico, N. Bertoldi, B. Cowan, W. Shen, C. Moran, R. Zens, C. Dyer, O. Bojar, A. Constantin, E. Herbst. 2007. Moses: Open Source Toolkit for Statistical Machine Translation. ACL 2007, Demonstration Session, Prague, Czech Republic
- ^ J. Niehues, 2007. Discriminative Word Alignment Models. Diplomarbeit at Universitat Karlsruhe (TH).
- ^ Moses Training Tutorial http://www.statmt.org/moses/?n=FactoredTraining.HomePage (页面存档备份,存于互联网档案馆)
- ^ Q. Gao, 2008 Parallelizing the Training Procedure of Statistical Phrase-based Machine Translation, Student Research Symposium Carnegie Mellon University. http://www.lti.cs.cmu.edu/SRS/2008-abstracts/talks/GaoTalk.pdf (页面存档备份,存于互联网档案馆)
外部链接
- Statistical Machine Translation (页面存档备份,存于互联网档案馆)—研究介绍、会议、语料及软件列表
- GIZA++:开源词对齐软件 (页面存档备份,存于互联网档案馆)
- MGIZA++/PGIZA++: GIZA++的并行化版本 (页面存档备份,存于互联网档案馆)
- Moses:开源机器翻译软件 (页面存档备份,存于互联网档案馆)
- Annotated list of statistical natural language processing resources (页面存档备份,存于互联网档案馆)