隐含狄利克雷分布(英语:Latent Dirichlet allocation,简称LDA),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。
LDA首先由 David M. Blei、吴恩达和迈克尔·I·乔丹于2003年提出[1],目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。
数学模型
LDA是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
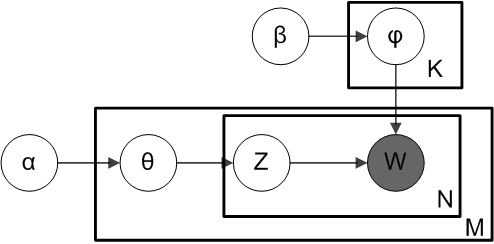
另外,正如Beta分布是二项式分布的共轭先验概率分布,狄利克雷分布作为多项式分布的共轭先验概率分布。因此正如LDA贝斯网络结构中所描述的,在LDA模型中一篇文档生成的方式如下:
- 从狄利克雷分布 中取样生成文档i的主题分布
- 从主题的多项式分布 中取样生成文档i第j个词的主题
- 从狄利克雷分布 中取样生成主题 的词语分布
- 从词语的多项式分布 中采样最终生成词语
因此整个模型中所有可见变量以及隐藏变量的联合分布是
-
最终一篇文档的单词分布的最大似然估计可以通过将上式的 以及 进行积分和对 进行求和得到
-
根据 的最大似然估计,最终可以通过吉布斯采样等方法估计出模型中的参数。
使用吉布斯采样估计LDA参数
在LDA最初提出的时候,人们使用EM算法进行求解,后来人们普遍开始使用较为简单的Gibbs Sampling,具体过程如下:
- 首先对所有文档中的所有词遍历一遍,为其都随机分配一个主题,即 ,其中m表示第m篇文档,n表示文档中的第n个词,k表示主题,K表示主题的总数,之后将对应的 , , , ,他们分别表示在m文档中k主题出现的次数,m文档中主题数量的和,k主题对应的t词的次数,k主题对应的总词数。
- 之后对下述操作进行重复迭代。
- 对所有文档中的所有词进行遍历,假如当前文档m的词t对应主题为k,则 , , , ,即先拿出当前词,之后根据LDA中topic sample的概率分布sample出新的主题,在对应的 , , , 上分别+1。
- ∝
- 迭代完成后输出主题-词参数矩阵φ和文档-主题矩阵θ
-
-
参见
- 万能翻译机
- 电脑语言学
- 受限自然语言
- 信息抽取
- 资讯检索
- 自然语言理解
- 潜在语义索引
- 潜在语义学
- 随机文法
- 机器记者
- 写作自动评分
- 生物医学文件探勘系统
- 复合词处理
- 计算语言学
- 电脑辅助审查
- 深度学习
- 深度语言处理
- 辅助外文阅读
- 辅助外文写作
- 语言科技
- 隐含狄利克雷分布(LDA)
- 母语识别
- 自然语言编程
- 自然语言使用者界面
- 扩展查询
- 具体化 (语言学)
- 语义折叠
- 语音处理
- 口语对话系统
- 校对
- 文字简化
- Thought vector
- Truecasing
- 问答系统
- Word2vec
参考文献
{kind=link}